Why I built SolvoKu
Some projects are made not for the expected result, but for the journey to attain it.
SolvoKu was built with this in mind.
Optimization Tips
This time it is about optimization!
Don't hesitate to give me your feedback.
Guard / Early exit in swift
A new article on the Swift section about early exit and guard in Swift.
New Swift section
As you might have noticed, a new 'Swift' section has appeared on this site.
This section is naturally about the Swift programming language.
It will includes some articles about things I find interesting about it.
Creating a bytecode based programming language, part 3
Third and last post about creating a compiler and an interpreter.
We convert each expression identified during the token reduction to an instruction (each expression kind is mapped to an instruction class).
The set of instruction objects obtained after having converted all expressions is the bytecode.
Now, how to we use it?
An instruction class is quite simple, it defines two methods: an init and a process one.
The init method has a single parameter: a token (or a complex token as it extends the token class). This token, or it's sub-tokens, is used to initialized the attributes of the instruction object.
The process method takes two parameters, firstly an execution output and then the execution context.
The execution output is mostly a StringBuffer.
The execution context is more complex. It contains access to information like the
Creating a bytecode based programming language, part 2
This is the long, or not, awaited second post about creating a compiler.
In this post we will talk about parsing a source code.
Creating a bytecode based programming language, part 1
This is the first of a series of short posts about a subject I am currently working on as a personal side project: creating a compiler to create bytecode based programming languages.
Read more…Implementing a VFS
While trying to implement a Virtual File System, that is to say a virtual representation of an hard drive with its folders and files, there are two main approach to consider:
- a tree based approach
- an absolute parent path approach
Ontology Oriented Programming
With ObjectOP, a software extract and analyze data to give informations. For knowledge to be created it require a human being to read this information. ObjectOP is a data processing approach, perfect to be used in a workflow or expert system.
In OntologyOP, the main purpose is to store, manage and create new information and knowledges using reasoning. Ontology is an information reasoning approach, appropriate for Knowledge Management Systems and Artificial Intelligence.
Creating a communicating app: what to think about
First of all, never assume your link will always be up and running.
- What to do if you can’t connect to your network ?
- What about if you got disconnected ?
- How and when will you notice a connection failure ?
Secondly, always avoid synchronized request, even if it’s true they are easier to create than asynchronous one.
- You can’t really cancel a synchronized request, you can only either destroy the thread it is running on, or wait for a timeout.
- With the asynchronous way you can start working on the result before it has been totally retrieved.
Thirdly, reduce the quantity of data you need to send and receive to a minimum.
If an XML message is easy to create and read, it has also a poor efficiency regarding the quantity of information it contains for the length of the message. Regarding transmission efficiency, the best method is to work on raw data, without any encapsulation, but it’s also the worst method considering debugging. A good alternative is the use of JSON, quite light and still human readable.
The fourth point concerns protocols designing. If you are conceiving your own one, you should keep in mind it may be subject to updates. That’s why it is always a good idea to send a version number in your messages. It would be helpful for maintaining compatibility with older versions of your software that would still work with an older protocol.
This list isn’t exhaustive and will most certainly be updated.
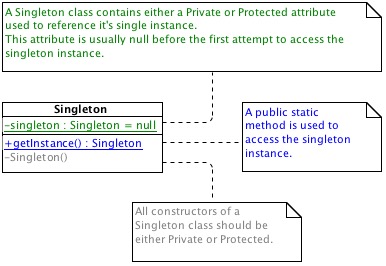
Design Pattern: Singleton
As the singleton instance can be accessed from anywhere in a system, this design pattern can be used to coordinate actions, or to replace global variables.
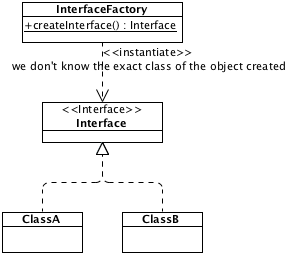
Design Pattern: Factory
That’s why a Factory return objets who are either :
- from a class extending a known abstract class,
- or from a class implementing a known interface.